Making vocab lists
The short version
I select the text I'm doing, exclude the vocab from my textbook and the core vocab lists, and export the principal parts and short definitions for everything but proper nouns/adjectives, plus the number of times the term appears in the text. I then import it into a spreadsheet program, sort by frequency, delete the frequency column, and export it back to a CSV for use in Anki.
The long version
For this tutorial, I'll be showing how I generated the vocab list for my Latin seminar last winter, in which we read the parts of Tacitus' Annals that dealt with Nero.
The first thing I need to do is open up Haverford Bridge and select "Latin". (I will note that the selection of Latin texts is much better than the selection of Greek texts.)
Press the "+" button at the bottom to add a text. I'm adding the Annals (which appear here as the Annales). Then I want to specify the sections of the book, so I select "yes" from the dropdown menu. Books 13 through the end of the text focus on Nero, so I'll be doing those (I'm just using "end" for the latter choice, because I don't remember exactly how many sections are in book 16).
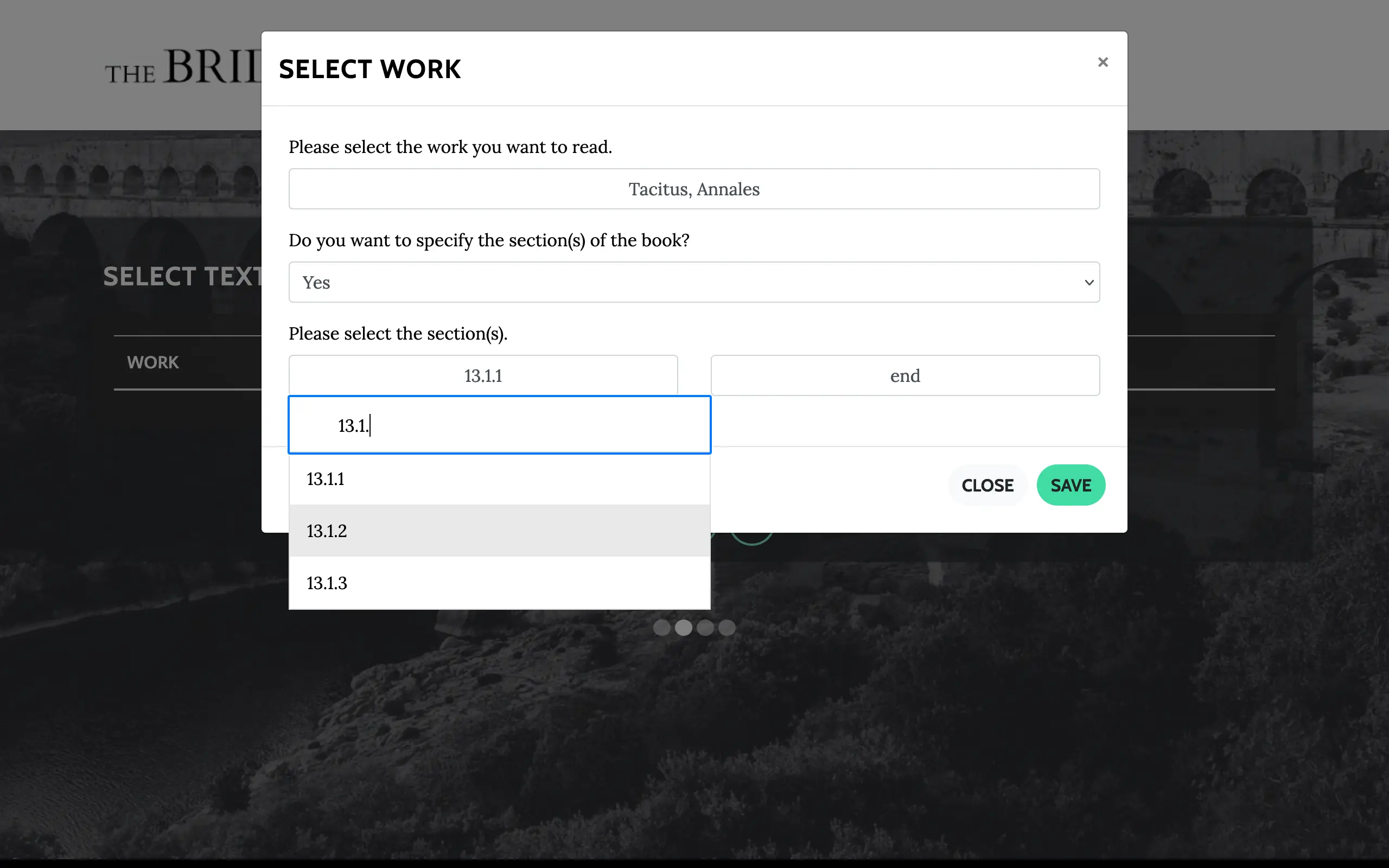
Save your choices. If you want to do multiple texts, you can press the "+" button again and do all this again. It is possible to put in enough selections to crash the site, but this only happened to me once and I had suspected it would be too much (I tried to generate a list for the entire Latin portion of my PhD reading list), so I wouldn't worry about it for any sort of normal use case.
Next, you have the option to cross-reference texts with those you chose in the previous step. You can choose to show only words that also appear in the newly added texts, or to exclude all words that also appear in the newly added texts. I usually use the latter to exclude the DCC core list and the vocabulary from the textbooks I used to learn Greek and Latin.
Click the check button, and it will generate your list, shown in order of first appearance.
Open the "options" tab at the side. In the "part of speech filters" section, I usually exclude proper nouns and adjectives, which can be done by pressing "refine" at the end of the list item and then unchecking the relevant box. (This usually doesn't catch all proper nouns/adjectives, but it at least saves me a bit of work.)
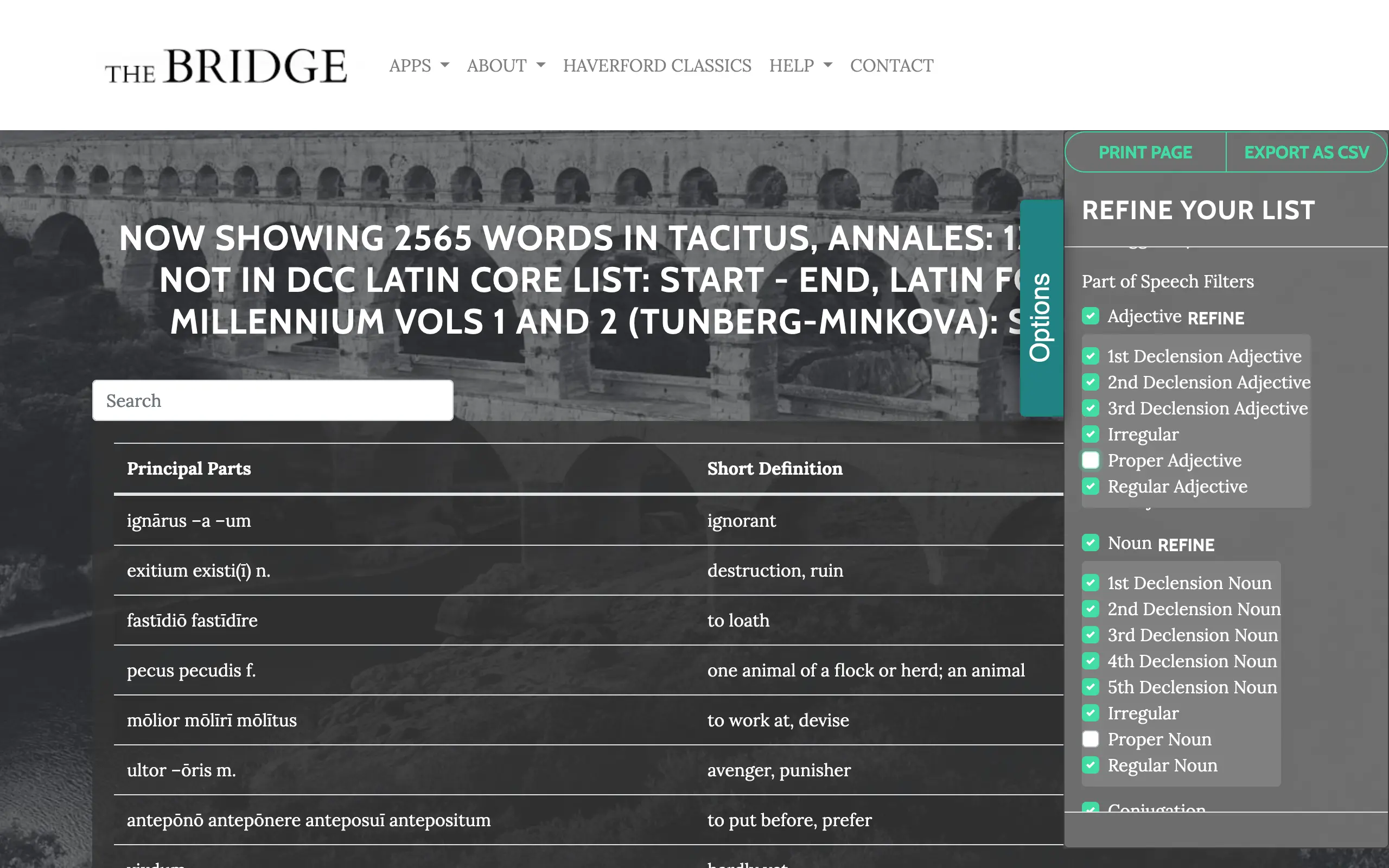
Under the "add or remove columns" section, I usually turn off "principal parts" and turn on "principal parts no diacriticals" for Latin. For both Latin and Greek, I turn on "count in selection". Then, at the top of the options menu, I "export as csv".
From there, I import it into my preferred spreadsheet program (Excel, Numbers, Sheets, etc.) and sort by "count_in_selection". I usually delete the least frequent words: depending on the length of the text, this can be words that appear up to three times. For a section this brief, I'm only going to be deleting words that appear once (which, for the record, reduces the number of words to learn from 3171 to 1740—a nearly 50% reduction). If I'm feeling it, I also delete any lingering proper nouns.
At this point, I delete the frequency column (as I won't be using it in my flashcards, now that the terms are in the right order). From there, I export the list as a CSV or TSV and import it into Anki, my preferred flash card program. You could easily do the same with Quizlet, Memrise, etc.